Машинное обучение: прогнозируем цены акций на фондовом рынке
Переводчик Полина Кабирова специально для «Нетологии», адаптировала статью инженера Кембриджского университета Вивека Паланиаппана о том, как с помощью нейронных сетей создать модель, способную предсказывать цены акций на фондовой бирже.
Машинное и глубокое обучение стали новой эффективной стратегией, которую для увеличения доходов используют многие инвестиционные фонды. В статье я объясню, как нейронные сети помогают спрогнозировать ситуацию на фондовом рынке — например, цену на акции (или индекс). В основе текста мой проект, написанный на языке Python. Полный код и гайд по программе можно найти на GitHub. Другие статьи по теме читайте в блоге на Medium.
Нейронные сети в экономике
Изменения в сфере финансов происходят нелинейно, и иногда может показаться, что цены на акции формируются совершенно случайным образом. Традиционные методы временных рядов, такие как модели ARIMA и GARCH эффективны, когда ряд является стационарным — его основные свойства со временем не изменяются. А для этого требуется, чтобы ряд был предварительно обработан с помощью log returns или приведён к стационарности по-другому. Однако главная проблема возникает при реализации этих моделей в реальной торговой системе, так как при добавлении новых данных стационарность не гарантируется.
Решением такой проблемы могут быть нейронные сети, которые не требуют стационарности. Нейронные сети изначально очень эффективны в поиске связей между данными и способны на их основе прогнозировать (или классифицировать) новые данные.
Обычно data science проект состоит из следующих операций:
- Сбор данных — обеспечивает набор необходимых свойств.
- Предварительная обработка данных — часто пугающий, но необходимый шаг перед использованием данных.
- Разработка и реализация модели — выбор типа нейронной сети и её параметров.
- Модели бэктестинга (тестирование на исторических данных) — ключевой шаг любой торговой стратегии.
- Оптимизация — поиск подходящих параметров.
Сбор данных
К счастью, необходимые для этого проекта данные можно найти на Yahoo Finance. Данные можно собрать, используя их Python API pdr.get_yahoo_data(ticker, start_date, end_date) или напрямую с сайта.
Предварительная обработка данных
В нашем случае данные нужно разбить на обучающие наборы, состоящие из 10-ти прошлых цен и цены следующего дня. Для этого я определил класс Preprocessing , который будет работать с обучающими и тестовыми данными. Внутри класса я определил метод get_train(self, seq_len) , который преобразовывает обучающие входные и выходные данные в NumPy массивы, задавая определенную длину окна (в нашем случае 10). Весь код выглядит так:
Аналогично я определил метод, который преобразовывает тестовые данные X_test и Y_test .
Модели нейронных сетей
Для проекта я использовал две модели нейронных сетей: Многослойный перцептрон Румельхарта (Multilayer Perceptron — MLP) и модель Долгой краткосрочной памяти (Long Short Term Model — LSTM). Кратко расскажу о том, как работают эти модели. Подробнее о MLP читайте в другой статье, а о работе LSTM — в материале Джейкоба Аунгиерса.
MLP — самая простая форма нейронных сетей. Входные данные попадают в модель и с помощью определённых весов значения передаются через скрытые слои для получения выходных данных. Обучение алгоритма происходит от обратного распространения через скрытые слои, чтобы изменить значение весов каждого нейрона. Проблема этой модели — недостаток «памяти». Невозможно определить, какими были предыдущие данные и как они могут и должны повлиять на новые. В контексте нашей модели различия за 10 дней между данными двух датасетов могут иметь значение, но MLP не способны анализировать такие связи.
Для этого используется LSTM или Рекуррентные нейронные сети (Recurrent Neural Networks — RNN). RNN сохраняют определенную информацию о данных для последующего использования, это помогает нейронной сети анализировать сложную структуру связей между данными о ценах на акции. Но с RNN возникает проблема исчезающего градиента. Градиент уменьшается, потому что количество слоев повышается и уровень обучения (значение меньше единицы) умножается в несколько раз. Решают эту проблему LSTM, увеличивая эффективность.
Реализация модели
Для реализации модели я использовал Keras , потому что там слои добавляются постепенно, а не определяют всю сеть сразу. Так мы можем быстро изменять количество и тип слоев, оптимизируя нейронную сеть.
Важный этап работы с ценами на акции — нормализация данных. Обычно для этого вы вычитаете среднюю погрешность и делите на стандартную погрешность. Но нам нужно, чтобы эту систему можно было использовать в реальной торговле в течение определенного периода времени. Таким образом, использование статистики может быть не самым точным способом нормализации данных. Поэтому я просто разделил все данные на 200 (произвольное число, по сравнению с которым все другие числа малы). И хотя кажется, что такая нормализация ничем не обоснована и не имеет смысла, она эффективна, чтобы убедиться, что веса в нейронной сети не становятся слишком большими.
Начнем с более простой модели — MLP. В Keras строится последовательность и поверх неё добавляются плотные слои. Полный код выглядит так:
С помощью Keras в пяти строках кода мы создали MLP со скрытыми слоями, по сто нейронов в каждом. А теперь немного об оптимизаторе. Популярность набирает метод Adam (adaptive moment estimation) — более эффективный оптимизационный алгоритм по сравнению с стохастическим градиентным спуском. Есть два других расширения стохастического градиентного спуска — на их фоне сразу видны преимущества Adam:
AdaGrad — поддерживает установленную скорость обучения, которая улучшает результаты при расхождении градиентов (например, при проблемах с естественным языком и компьютерным зрением).
RMSProp — поддерживает установленную скорость обучения, которая может изменяться в зависимости от средних значений недавних градиентов для веса (например, насколько быстро он меняется). Это значит, что алгоритм хорошо справляется с нестационарными проблемами (например, шумы).
Adam объединяет в себе преимущества этих расширений, поэтому я выбрал его.
Теперь подгоняем модель под наши обучающие данные. Keras снова упрощает задачу, нужен только следующий код:
Когда модель готова, нужно проверить её на тестовых данных, чтобы определить, насколько хорошо она сработала. Это делается так:
Информацию, полученную в результате проверки, можно использовать, чтобы оценить способность модели прогнозировать цены акций.
Для модели LSTM используется похожая процедура, поэтому я покажу код и немного объясню его:
Обратите внимание, что для Keras нужны данные определенного размера, в зависимости от вашей модели. Очень важно изменить форму массива с помощью NumPy.
Модели бэктестинга
Когда мы подготовили наши модели с помощью обучающих данных и проверили их на тестовых, мы можем протестировать модель на исторических данных. Делается это следующим образом:
Однако, это упрощенная версия тестирования. Для полной системы бэктестинга нужно учитывать такие факторы, как «ошибка выжившего» (survivorship bias), тенденциозность (look ahead bias), изменение ситуации на рынке и транзакционные издержки. Так как это только образовательный проект, хватает и простого бэктестинга.
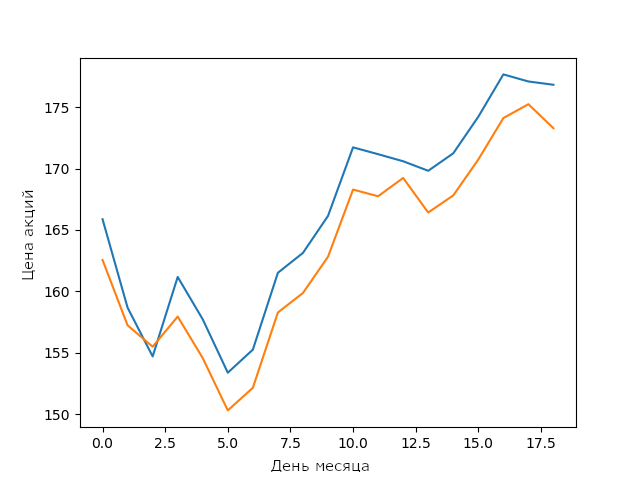
Прогноз моей модели LSTM на цены акций Apple в феврале
Для простой LSTM модели без оптимизации это очень хороший результат. Он показывает, что нейронные сети и модели машинного обучения способны строить сложные устойчивые связи между параметрами.
Оптимизация гиперпараметров
Для улучшения результатов модели после тестирования часто нужна оптимизация. Я не включил её в версию с открытым исходным кодом, чтобы читатели могли сами попробовать оптимизировать модель. Тем, кто не умеет оптимизировать, придется найти гиперпараметры, которые улучшат производительность модели. Есть несколько методов поиска гиперпараметров: от подбора параметров по сетке до стохастических методов.
Я уверен, с оптимизацией моделей знания в сфере машинного обучения выходят на новый уровень. Попробуйте оптимизировать модель так, чтобы она работала лучше моей. Сравните результат с графиком выше.
Вывод
Машинное обучение непрерывно развивается — каждый день появляются новые методы, поэтому очень важно постоянно обучаться. Лучший способ для этого — создавать интересные проекты, например, строить модели для прогноза цен на акции. И хотя моя LSTM-модель недостаточно хороша для использования в реальной торговле, фундамент, заложенный при разработке такой модели, может помочь в будущем.
Машинное обучеине и трейдинг

Проявлением наибольшего милосердия в нашем мире является, на мой взгляд, неспособность человеческого разума связать воедино все, что этот мир в себя включает. Мы живем на тихом островке невежества посреди темного моря бесконечности, и нам вовсе не следует плавать на далекие расстояния.
На Смартлабе что-то активизировались дискуссии о возможности использования методов машинного обучения (нейронных сетей как их частный случай) в трейдинге. У меня сложилось ощущение, что дискутирующие совсем не понимают что это за зверь такой — машинное обучение (ML) и зачем он нужен.
Предположим есть задача: зная силу, с которой ударяют по мячику и его массу описать его движение. Можно ли эту задачу решить методами ML? Ну, наверное можно, но не нужно  Классическая механика сделает это куда быстрее, надежнее, точнее. Или же пример поближе: зная себестоимость, среднюю цену продажи и объем продаж можно предсказать валовую прибыль.
Классическая механика сделает это куда быстрее, надежнее, точнее. Или же пример поближе: зная себестоимость, среднюю цену продажи и объем продаж можно предсказать валовую прибыль.
А что если мы не знаем массу мячика? Ну, можно провести один или несколько опытов, а по ним уже, зная (из механики) уравнения движения, её определить, чтобы в дальнейшем использовать для предсказаний. Опять пример поближе: узнав маржу по первому кварталу, и зная производственные планы, можно прикинуть прибыль за год (привет, СарНПЗ)!
Однако, у примеров выше есть особенность: 1) количество неизвестных параметров невелико, и, что еще более важно 2) функциональная зависимость от параметров примерно понятна. Впрочем, существует множество задач, где и число параметров, которые нужно варьировать велико и/или где функциональную зависимость так просто не описать. Вот именно для таких задач и нужно машинное обучение!
Например, чтобы выиграть в шахматы надо не иметь больше фигур на доске, а поставить сопернику мат. Однако, число возможных вариантов развития событий — последовательностей ходов, относительно невелико. Поэтому, успешно реализовав алгоритм «брутфорса», компьютер уже давно стал выигрывать у человека. Но например в го, цель игры проще — иметь больше очков на конец игры. Только вот вариантов на порядки больше — создать алгоритм игры так, чтобы машина выигрывала у человека не получалось. Однако методами ML это сделать получилось — смогли придумать как возможным ходам приписать функцию «полезности» которая каким-то сложным образом зависит от каких-то других известных параметров и подобрать в этой сложной функции нужные коэффициенты. Разумный вопрос: а почему обычными методами то не получалось? Потому что все попытки описать «полезность» хода через какие-то разумные функциональные зависимости терпели крах. Ну на островке невежества живем, ничего с этим поделать нельзя. Пришлось уплывать туда, что и описать никаким человеческим языком то нельзя.
Резюмируя эту часть поста: отнюдь не верно считать, что «машина умеет думать». Не умеет. Компьютер лишь умеет осуществлять математические операции; точно и куда быстрее человека. А то что суслика не видно, не означает, что его нет :)) Грубо говоря, методы машинного обучения о том, как из множества параметров составить сложного вида функцию, подобрать к ней коэффициенты так, чтобы на выходе получался хороший результат. Сложная многомерная оптимизация одной фразой.
Вернемся к трейдингу Можно ли делать деньги на бирже с помощью создав методами машинного обучения алгоритм совершения сделок? Ответ на этот вопрос напрямую зависит от другого вопроса: можно ли делать деньги теханализом? Если да — то тогда вполне возможно создать торговую стратегию, основанную на методах машинного обучения. Более того, их со временем станет все больше, да и предсказывать рынок они научатся куда лучше людей.
В заключение, необходимо отметить, что главная сила машинного обучения является же и его главной слабостью. Ежели при анализе обычными методами надо думать о том: разумны ли предположения, что функциональная зависимость носит такой вот характер; разумны ли параметры; где и как это будет, а где не будет работать и т.д., то с ML все просто: машина обучилась делать так и всё . А как влияет тот или иной параметр на результат (и влияет ли вообще) вам никто не скажет, да и проанализировать это по сути невозможно .
Иными словами: совершили вы убыточную сделку, или лучше ряд убыточных сделок. Что это? Просто «человеческая» оплошность? Полоса неудач? Неправильный выбор стратегии? И если последнее, то можно ли этого избежать подкорректировав стратегию? Обычными методами эти вопросы как минимум можно обдумать (а возможно и получить правильный ответ). Используя алгоритмы на основе машинного обучения вам останется только надеяться, что все ок.
Что такое машинное обучение в трейдинге
Машинное обучение в трейдинге — это метод искусственного интеллекта, необходимый для автоматического изменения алгоритмов и автоматической проверки их производительности.
С момента своего изобретения машинное обучение активно применяется в сфере финансовых технологий. Модели прогнозов были первыми приложениями искусственного интеллекта в финансовом секторе, которые оказались полезными. Поэтому финансовые компании начали вкладывать средства в программы машинного обучения, хотя какое-то время назад это считалось неперспективным.

Могут ли машины торговать лучше людей?
Торговля требует большого внимания и чувствительности к рынку. Опытные трейдеры полагаются на множество источников информации:
- новости;
- исторические данные;
- отчетность;
- сообщения от инсайдеров компании и много другое.
Риск высок, и необходимо учитывать множество переменных. По этой причине некоторые финансовые учреждения полагаются исключительно на машины для совершения сделок. Это означает, что компьютер с высокоскоростным подключением к интернету может выполнять тысячи сделок в течение дня, получая прибыль от небольшой разницы в ценах. Это называется высокочастотной торговлей. Ни один человек не может конкурировать с этими алгоритмами, они очень быстрые и точные.
Обратной стороной этого подхода является то, что средний человек может не иметь доступа к таким инструментам, так как они слишком дорогие. Однако с такими торговыми платформами, как Robinhood или TD Ameritrade, любой человек может играть на фондовом рынке со своего компьютера или смартфона. И вам даже не нужно платить брокерские сборы, что делает автоматическую торговлю очень привлекательной для новичков. Давайте разберемся можно ли использовать машинное обучение для прогнозирования движения цены на финансовых рынках?
Как работает машинное обучение в торговле
Трейдеры пользуются алгоритмами машинного обучения, чтобы повысить надежность прогнозов входной информации. Предсказания основываются на других алгоритмических программах, которые разрабатываются другими фирмами, однако и эти прогнозы можно улучшить.
Удобный трюк, которым пользуются специалисты по трейдингу с помощью машинного обучения, — это объединение различных прогнозов в один, который в таком случае получается более точным. Это называется ансамблем, и он работает очень хорошо.
Торговля заключается в выявлении определенных структур, которые ограничиваются временем и пространством, и правильном их использования. Процесс поиска закономерностей человеком трудоемок и занимает много часов.
Однако алгоритмы ИИ — отличные машины для нахождения этих закономерностей. Когда трейдер предполагает нарушение в определенном потоке данных, он может ускорить процесс поиска с помощью машинного обучения.
То есть искусственный интеллект может выявлять нужный паттерн, если им управляет профессиональный трейдер, который понимает, что ему нужно искать. После чего паттерны могут использоваться остальными трейдерами, которые подключают к этому свой опыт и аналитические способности. Также можно использовать алгоритмы для создания автоматических торговых систем.
В высокочастотной торговле машины выполняют по сто тысяч сделок в сутки, используя недостатки, заметные в максимально коротких промежутках времени. Человек не может заниматься таким трейдингом, так он физически не успеет обдумать весь процесс, однако роль человека заключается в определении правил, по которым работает алгоритм.
Стоит учесть, что условия на рынке подвержены частым изменениям, поэтому торговые роботы подлежат постоянной настройке. Что занимает большое количество сил и времени.Тут на помощь приходит машинное обучение, с помощью которого можно автоматизировать повторные калибровки. То есть искусственный интеллект выполняет много монотонной работы, которая в противном случае ложилась бы на плечи игроков.
ИИ сегодня умнее людей?
Если смотреть правде в лицо, даже очень современные алгоритмы машинного обучения сегодня очень примитивны относительно мозга человека.
Когда ИИ побеждает шахматиста в партии, это просто означает, что машина обгоняет человека в гонке. Естественно, машина более быстрая, но от этого она не становится лучше, она лишь отлично выполняет очень узкопрофильное назначение в определенном потоке условий.
Стоит отметить, что трейдинг не является узкой задаче. Торговля — это всегда широконаправленная конкуренция с другими людьми, которые используют все свои умственные способности, чтобы перехитрить вас.
Однако построить торговый алгоритм, который сможет обхитрить рынок, может оказаться простой задаче, если вы забываете о всех расходах при совершении сделок. В таком случае комиссия за транзакционные издержки и проскальзывание съест большую часть прибыли. Этого хватит, чтобы стереть доход, полученный при моделировании.
Важной концепцией машинного обучения является нахождение последовательностей в исторических данных, чтобы применить их для прогнозирования будущей цены. Однако в трейдинге это не всегда действует правильно. Игроки соревнуются в поиске тех же паттернов, поэтому паттерны обнаруживаются, используются, а затем перестают работать. Это значит, что шаблон существует непродолжительное время, и вам нужно время от времени пребывать в поиске новых.В этом аспекте сейчас люди намного лучше ИИ.
Сам по себе алгоритм не даст вам преимущества. Потому что данные, которые вы передаете своему алгоритму, значат гораздо больше для успешной торговли. Следовательно, алгоритмический прогноз, всегда будет отставать от прогноза профессионального трейдера, с условием, если не ограничен в потоке данных.

Где лучше всего работают алгоритмы?
Плодородной почвой для алгоритмов могут быть неэффективные рынки. То есть рынки с небольшим количеством участников торгов, высоким барьером для входа, небольшим объемом торгов и небольшим количеством игроков. Здесь использование ИИ может действительно принести успех в торговлю.
На этих рынках автоматический трейдинг, в частности машинное обучение, только появляются, и торговцы, которые создают механизмы автоматической торговли, могут оказаться лидерами в получении хорошей прибыли.
Источник https://habr.com/ru/company/netologyru/blog/428227/
Источник https://smart-lab.ru/blog/682453.php
Источник https://xcritical.com/ru/blog/ispolzovanie-mashinnogo-obucheniya-v-treydinge/




